PHP是速度很快的脚本语言,但是用了框架以后好像感觉挺慢的。于是猜测会不会PHP本身也不是很快。如果不是很快,能否采用PHP调用本地动态链接库的形式来提升速度。 于是有了下面的对比实验。
测试环境
1. 硬件环境如下图所示。
2. 软件环境
系统: Ubuntu 12.10
gcc版本:
Thread model: posix
gcc version 4.7.2 (Ubuntu/Linaro 4.7.2-2ubuntu1)
php版本:
PHP 5.3.22 (cli) (built: Mar 14 2013 20:37:16)
Copyright (c) 1997-2013 The PHP Group
Zend Engine v2.3.0, Copyright (c) 1998-2013 Zend Technologies
php开发环境: LAMP,所有安装包均是通过源码编译安装而成,编译过程中会自动根据本机各项参数进行最优配置。性能比apt-get install命令直接安装好。 关于以源码包方式搭建LAMP请参考文章:http://keping.me/linux-php-dev-by-source-style/
测试方法
由于冒泡排序在时间复杂度上相当稳定——O(n2),在最大程度上减少了数据可能带来的影响,故采取计算冒泡排序的运行时间的方法来进行此次实验。
对比测试分组
分组1: C++直接调用程序内的函数
分组2: C++调用打包好的动态链接库文件(.so文件,该文件也是自己写好并打包)
分组3: PHP直接调用程序内的函数
分组4: PHP调用打包好的动态链接库文件(.so文件,该文件也是自己写好并打包)
测试数据
数据总体规模为5,500,000个0~999的整数。
每一实验组,循环执行次数为30250,000,000,000次。
测试所用数据可以从以下地址下载:
http://keping.me/david-uploads/data/data_cpp.tar.gz
测试数据生成代码如下
[cpp]
#include
#include
#include
using std::cout;
using std::endl;
int main (int argc, char *argv[])
{
int scale;
scale = atoi(argv[1]); // argv[1] will be 10000, 20000 … 90000, 100000
srand(unsigned(time(0))); // use the UNIX timestamp as seeds
for(int i = 1; i <= scale; i++)
{
cout << rand() % 1000 << "\t";
if(i % 10 == 0) cout << endl;
}
}
[/cpp]
可以看到是0~999的整数,一共有10种测试数据的规模,分别放在十个不同目录下,如下图所示
![]()
目录名称代表数据的规模,如data_90000 表示数据规模为90,000个,同理data_100000表示数据规模为100,000个,依次类推。每一个目录下面包含10组测试数据,以data_100000举例,如下图所示
![]()
每个文件则包含100,000个0~999的随机数
数据文件打包下载地址: 地址1(包含数据以及 “分组1” 的测试结果)
以下是对比测试。
首先是 “分组1” 的测试
为了尽量保证算法一致,所以没有采用指针等数据结构,变量的交换也采用最原始的设置中间变量机制,关键代码如下:
[cpp]
void bubble(int *arr, int len)
{
int tmp;
for(int i = 0; i < len – 1; i++)
{
for(int j = i + 1; j < len; j++)
{
if(arr[i] > arr[j])
{
tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
}
}
}
[/cpp]
以下是data_100000目录下num_1数据文件的运行结果文件result_1的部分截图, 用时13.74秒
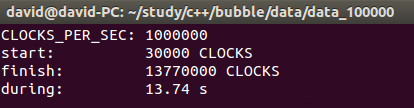
第一行输出记录的是每一秒中所含的时钟数;第二行记录的是排序开始之前程序已经运行的时钟数;第三行记录的是排序结束以后程序运行的时钟数;第四行则可以根据前面的数据得出本次排序运行的时间,以秒记,保留两位小数便于对比。
下表则是data_100000目录下的所有数据文件(num_1 至 num_9)的运行结果
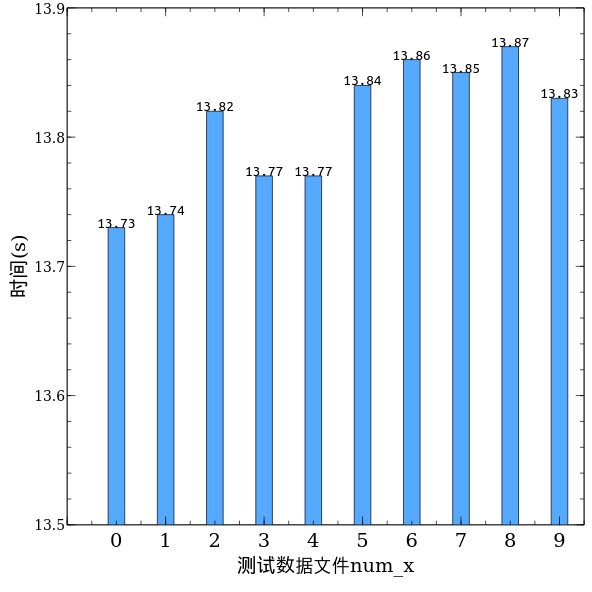
可以看到,对于100,000级别的数据,进行冒泡排序, “分组1” 用了大约13.8秒左右的时间。下面将给出对于不同数据规模(data_10000~data_100000)的平均测试数据
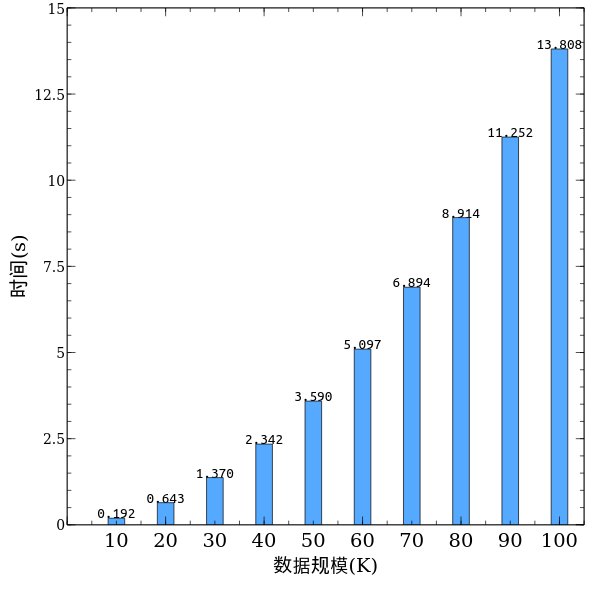
其中X轴方向上表示数据规模为 10K(即使10,000),20K,,,100K的测试数据。
其中Y轴方向上表示测试的平均时间,对每一数据规模均有10个测试数据,此处为平均值。
从图中可以看出,结果基本符合 y=x2 的函数曲线,冒泡排序还是相当稳定的。。。
分组2的测试
目录结构如下,其中libbubble.so文件即为冒泡排序打包成动态链接库。将会在main函数中调用。分组2与分组1的主要区别也在此,分组1中是在main里调用本地的冒泡排序函数,而分组2则是通过调用.so文件中的冒泡排序函数。

运行的测试数据来源与“测试分组1”完全一致,测试结果储存在相应目录下,如下图所示。
将测试结果的数据处理以后,得到下图。
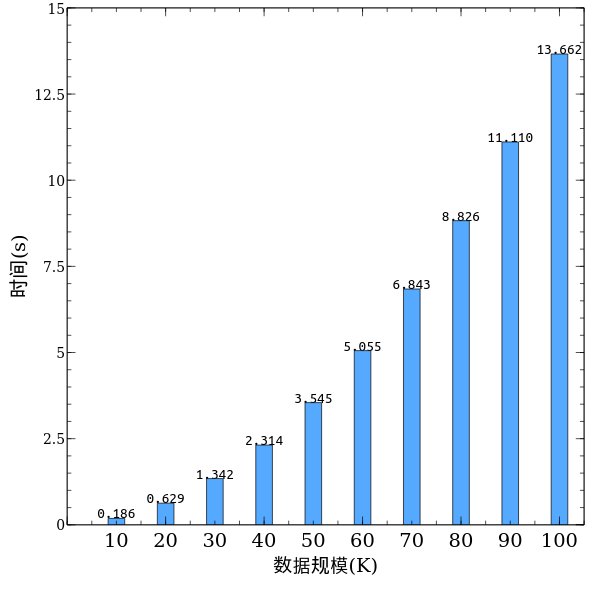
速度竟然比C++调用自己内部的函数更快,估计是打包成动态链接库的时候,编译器已经做了优化。
分组3的测试
接下来是PHP执行冒泡排序的测试。
目录结构如下图所示,将调用PHP写的冒泡排序函数进行数据测试。 关

关键代码如下
[php]
for($i = 0; $i < $len – 1; $i++)
{
for($j = $i + 1; $j < $len; $j++)
{
if($arr[$i] > $arr[$j])
{
$tmp = $arr[$i];
$arr[$i] = $arr[$j];
$arr[$j] = $tmp;
}
}
}
[/php]
可以看到,为了保证算法上的一致性,代码结构与实验分组一是一样的。
由于实在是比较慢,所以写了一个shell脚本来执行,shell脚本如下图所示(未完整截图)
将分组3的测试结果的数据处理以后,得到下图。
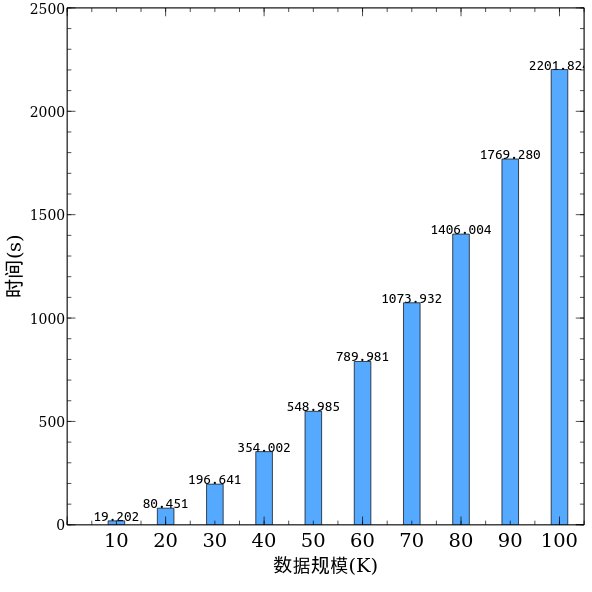
可以看到在相同数据规模下,分组3的运行时间要远远大于分组1以及分组2,并且随着数据规模的上升,总体呈现出上升趋势。
分组4的测试
分组4与分组3的区别在于:分组4则是调用以C++编写的动态链接库中的冒泡排序算法,并将该动态链接库以扩展的形势添加到了PHP系统中;分组3则是直接调用PHP写的冒泡排序算法。
将分组4的测试结果的数据处理以后,得到下图。
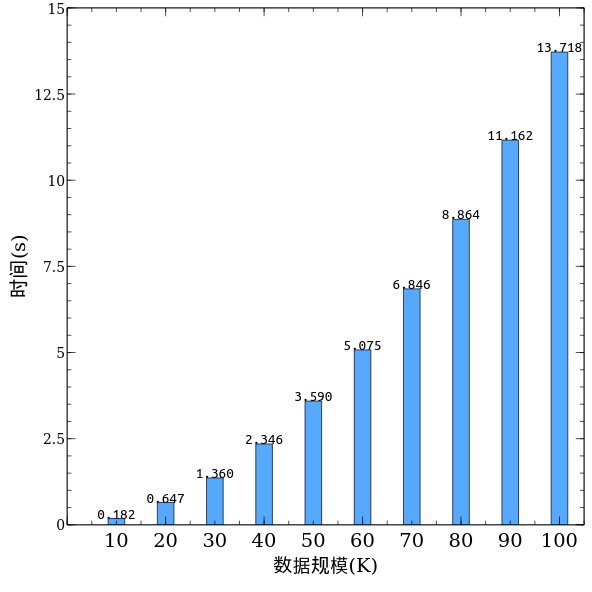
可以看到虽然还是PHP进行冒泡排序算法,但是效率得到了极大的提高。
最后是对比图
首先看一下数据表

其中10000,20000, …, 100000代表数据规模,表中数据为执行的秒数。可以看到分组3,也就是PHP分组,大约是其他分组的100倍至170倍时间。以至于如果不采取log函数,将完全看不到其他三个分组的图。下图是对上表每个数据取以10为底的对数以后,得到的数值描绘的图。
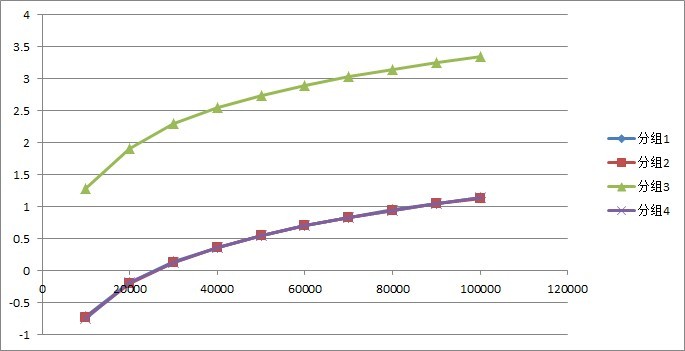
大致结论,PHP执行速度很慢,如果实在要采取PHP的方式,请采用将C/C++编写的动态链接库,经过Zend API的转化添加成PHP扩展,PHP再调用该扩展的形势,性能如分组4所示,是非常快的。
参考文献
[1] Al-Qahtani, S. S., Arif, R., Guzman, L. F., Pietrzynski, P., & Tevoedjre, A. (2010). Comparing selected criteria of programming languages java, PHP, C++, perl, haskell, AspectJ, ruby, COBOL, bash scripts and scheme revision 1.0.Cornell University.
[2] Sterling Hughes. Extending PHP [J]. Web Techniques, 2001, 6(1), 56 – 60.
[3] PHP, http://www.php.net/manual/en/internals2.structure.php
[4] Wikipedia, PHP, https://en.wikipedia.org/wiki/PHP