只熟悉C,对C++不甚了解啊,但是面试又基本只有C++和Java的。于是乎,整理一下自己遇到的C++面试/笔试题吧
———————————————–我是背景———————————————————————
题目一:一个C++空类建立以后,会产生哪些成员函数?
分析:当时我就只想到了构造和析构函数啊。答案是6个。
[cpp]
class Empty
{
public:
Empty(); // 缺省构造函数
Empty( const Empty&); // 拷贝构造函数
~Empty(); // 析构函数
Empty& operator=( const Empty&); // 赋值运算符
Empty* operator&(); // 取址运算符
const Empty* operator&() const; // 取址运算符 const
};
[/cpp]
但并不一定是6个,如果编译器发现我们只是申明了Empty,并没有发现创建Empty的实例,那么编译器是什么函数都不会生成的。
所有这些只有当被需要才会产生。比如,
Empty e;
编译器就会根据上面的实例,给类Empty生成构造函数和析构函数。
当使用
Empty e2(e);
编译器就会生成类Empty的拷贝构造函数。
Empty e3;
e3 = e;
编译器生成赋值运算符函数
Empty &ee = e;
编译器生成取地址运算符函数。
经过我们的分析可以这样理解:对于一个没有实例化的空类,编译器是不会给它
生成任何函数的,当实例化一个空类后,编译器会根据需要生成相应的函数。这条理论同样
适合非空类(只声明变量,而不声明函数)。
———————————————————————————————————————————–
题目二:STL中,vector与list的区别?
分析:其实基本就是 数组 与 双向链表 的区别,所以就很显然啦。
vector能够很好的支持随机访问,即有下标操作[],但如果要插入或者删除一个数则需要较多次数的移动元素。
list能够很好的支持插入、删除操作,但由于没有下标操作[],所以查找一个元素的时候比较耗时。
———————————————————————————————————————————–
题目三:内联函数、宏的区别?
分析:
由于内联函数首先它是一个函数,所以可以从宏与普通函数的对比入手,先引用一下别人的总结。
(1)、宏只做简单的字符串替换,函数是参数传递,所以必然有参数类型检查(支持各种类型,而不是只有字符串)以及类型转换。
(2)、宏不经计算而直接替换参数,函数调用则是将参数表达式求值再传递给形参。
(3)、宏在编译前(即预编译阶段)进行,先替换再编译。而函数是编译后,在执行时才调用的。宏占编译时间,而函数占执行时间。
(4)、宏参数不占空间,因为只做字符串替换,而函数调用时参数传递是变量之间的传递,形参作为局部变量占内存空间。
(5)、函数调用需要保留现场,然后转入调用函数执行,执行完毕再返回主调函数,这些耗费在宏中是没有的。
使用宏和内联函数都可以节省在函数调用方面的时间和空间开销。二者都是为了提高效率,但是却有着显著的区别:
(1)、内联函数首先是函数,函数的许多性质都适用于内联函数(如内联函数可以重载)。
(2)、在使用时,宏只做简单的文本替换。内联函数可以进行参数类型检查,且具有返回值(也能被强制转换为可转换的合适类型)。
(3)、内联函数可以作为某个类的成员函数,这样可以使用类的保护成员和私有成员。而当一个表达式涉及到类保护成员或私有成员时,宏就不能实现了(无法将this指针放在合适位置)。
———————————————————————————————————————————–
题目四:实现一个算法,删除字符串重复字符
分析:当时笔试面试已经搞了一下午,头晕眼花,第一次还写错了。回来整理了一下,其实很简单。
用两个指针p, q遍历待处理的字符串str,p负责记录有效位,q负责往前扫描。初始化q指向p的下一个字符。
(1) 如果p的字符和q的字符不等,那么由p记录下来,p与q均往前移动一个字符
(2) 如果p的字符和q的字符相等,那么p不动,q往前移动一个字符
代码如下
[cpp]
// the input str must terminated by ‘\0’
char* str_rm_dup(char *str)
{
char *p = str;
char *q = p;
// if str is NULL, then return
if(!p)
return NULL;
/*
* Assign q to the next address of p.
* Before that, we use *q++, not *++q to check whether *p == ‘\0’ in the first loop,
* because if the str is an empty string, str[0] will be ‘\0’.
*/
while(*q++)
if(*p != *q)
*++p = *q;
return str;
}
int main()
{
char a[] = "aabbbccdeeeeee";
printf("%s\n", str_rm_dup(a)); // abcde
return 0;
}
[/cpp]
———————————————————————————————————————————–
题目五:要求写一个没有错误的二分
分析:主要就是注意两点
(1) 整数相加溢出,比如4位机器上,a和b都等于7,即0111,那么相加就悲剧了。
(2) 防止无限循环
代码如下
[cpp]
/*
* Find the index of v if it is in the array of interval [a, b), -1 if not.
* @para a, the first location of the NOT DESC array
* @para l, the lowest index of the interval to be searched
* @para h, the highest index of the interval to be searched
* @para v, the candicate value
* @return index of v, or -1 if not found
*/
int bs(int *a, int l, int h, int v)
{
int m;
while(l < h)
{
m = (unsigned)l + (unsigned)h >> 1; // avoid the overflow of integer
if(a[m] == v)
return m;
if(a[m] < v)
l = m + 1;
else
h = m;
}
return -1;
}
[/cpp]
———————————————————————————————————————————–
题目六:深拷贝、浅拷贝区别?
分析:我的理解就是,浅拷贝只简单赋值,深拷贝是在需要的时候申请新的内存空间。假设我们有一个简单类A,代码如下所示:
[cpp]
class A
{
public:
A(char *s) : str(s) {}
void display()
{
cout << str << endl;
}
public:
char *str;
};
[/cpp]
然后我们写一个简单的main函数来调用它,如下
[cpp]
int main(void)
{
char name[] = "David";
A a(name);
A b = a;
a.display();
b.display();
b.str[0]=’P’;
a.display();
b.display();
return 0;
}
[/cpp]
结果为
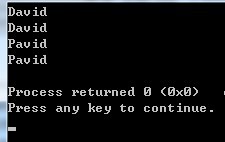
这是由于我们在类A中并没有去实现拷贝构造函数,编译器则帮我们实现了一个默认的,默认的构造函数则是简单的变量赋值,所以对象a和b的str成员变量其实指向的是同一块儿内存。所以改了一个,另外一个也会跟着改变。
下面我们修改一下类A,代码如下
[cpp]
class A
{
public:
A(char *s) : str(s) {}
void display()
{
cout << str << endl;
}
A(const A &another)
{
str = (char*)malloc(sizeof(char) * (strlen(another.str) + 1));
strcpy(str, another.str);
}
public:
char *str;
};
[/cpp]
然后看运行结果
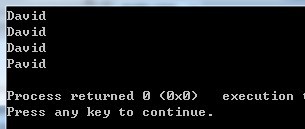
这次对象a和b的str由于指向的不是同一块儿内存地址,所以改了b的str对a不会造成影响。
还有一个区别是,貌似在消除对象a或者b的时候,如果是浅拷贝,会删除两次str所指的内存空间,会造成不可预料的结果。但是我跑程序暂时还未出现崩溃。
———————————————————————————————————————————–